
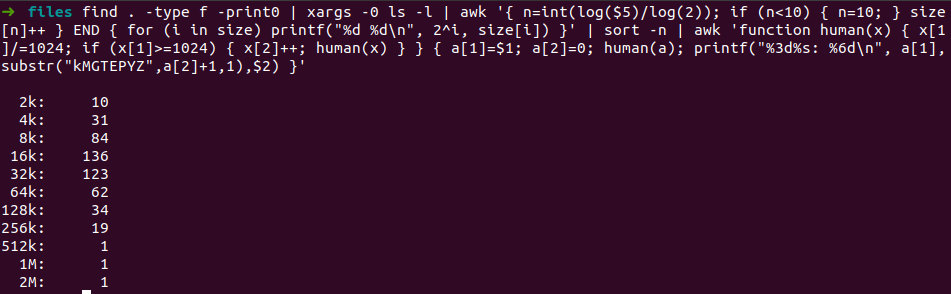
I’m a sucker for a good shell command and recently discovered (via StackOverflow) the most complex one yet - a one liner to generate a histogram of file sizes within a directory. The sizes are in powers of two but it’s a great way to get some simple summary statistics of files inside a directory. I still find awk mystifying to write but nearly every advanced shell command uses awk in some way. Most engineers thee days have a bias for a traditional scripting language but it’s still amazing what an awk one-liner can do.
find . -type f -print0 | xargs -0 ls -l | awk '{ n=int(log($5)/log(2)); if (n<10) { n=10; } size[n]++ } END { for (i in size) printf("%d %d\n", 2^i, size[i]) }' | sort -n | awk 'function human(x) { x[1]/=1024; if (x[1]>=1024) { x[2]++; human(x) } } { a[1]=$1; a[2]=0; human(a); printf("%3d%s: %6d\n", a[1],substr("kMGTEPYZ",a[2]+1,1),$2) }'