
Lately I’ve found myself thinking more deeply about the code I’m writing. No matter how small the task or script I’ll think through the implications of my approach and whether I should be doing anything differently. This doesn’t mean I’ll always pick the more correct and flexible approach and more often than not I’ll choose the quick and dirty one to save time but the thought process itself is valuable since it gets me in the habit of questioning and constantly improving my code. The following is an example that illustrates this approach.
Years ago I wrote a basic app that shows the most popular Hacker News stories over a 24 hour period. It crawls the Hacker News homepage every 15 minutes and parses the DOM in order to track a story’s total points along with a few additional stats. It’s an extremely simple script that’s been running unchanged for multiple years. And yet a few days ago while checking up on it I discovered that there was a minor bug - there was a small change to the HTML structure which caused the number of comments to no longer be parsed.
The screenshot below shows a typical Hacker News entry - the top row contains the title and the domain and the bottom row has the points, the submitter, and the comments. Looking at the source code we can see that the number of comments is part of the last <a> entry in the bottom row.
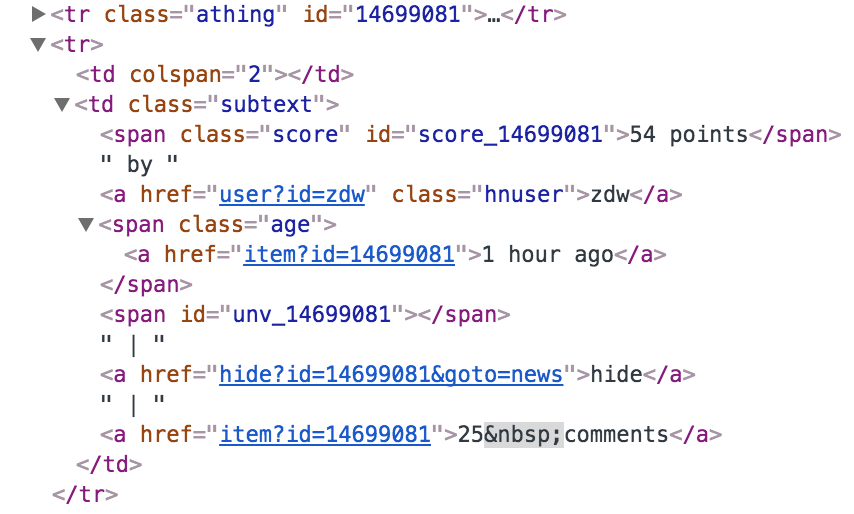
When I wrote the code years ago it was the second entry so all my code did was look at the second <a> element and extract the number. At some point over the past few years the flag and hide options were added which caused my logic to fail. The fix was to look at the new element containing the comments but there are multiple ways to handle it. The simplest is to just realize it’s the 4th element and go off of that - but once again if the structure changes we will run into the same issue we just did. Another approach is look at the last element in which case we’ll be good as long as the comments element is always the last one. Yet another approach is to go through each of the cells and search for the “comment” string. If we find it then we use that cell, otherwise we move on until we do. This will work no matter where the comments section since we’re going through each one. With significant effort, one can even extend this into a learning system that is able to infer where the various bits of content are in a wide range of possible structures. There’s no right answer and it’s a series of tradeoffs but it illustrates how there’s significant depth and choice in the simplest of coding problems. Hundreds of these seemingly minor choices occur every time we write a script and thousands when writing a large project. Getting into the habit of questioning our choices is how we end up writing wonderful code as a habit.