
I’m a sucker for data visualizations so when I came across a simple word cloud-generating Python script I knew I had to give it a shot. Lucky for me I’ve been blogging fairly consistently since the beginning of 2013 and have a large text set to visualize. The first step was generating a word cloud for every single post I wrote and the second was to break it down by year. This didn’t reveal too much but got me thinking about how my writing has changed over the years. This led my discovery of a script on StackOverflow that works by translating each block of text into an tf-idf (term frequency - inverse document frequency) vector and then calculating the cosine distance between them. This intuitively makes sense. The tf-idf vector is used to highlight and quantify the unique words in a given document as a vector and the cosine distance is used to compare the similarities between them - if they vectors are equivalent the angle between them is 0 which has a cosine of 1. Turns out that high school math is incredibly useful.
A word cloud across every blog post.
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2008 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2009 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2010 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2011 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2012 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2013 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2014 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2015 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
<p>A word cloud for 2016 blog posts.</p>
</div>
</li>
<li>
<div class="thumbnail">
<img src="/image/blogging-similiary-2008-2016.png" alt="Blog post similarity 2008-2016" data-width="2648" data-height="706" data-layout="responsive" />
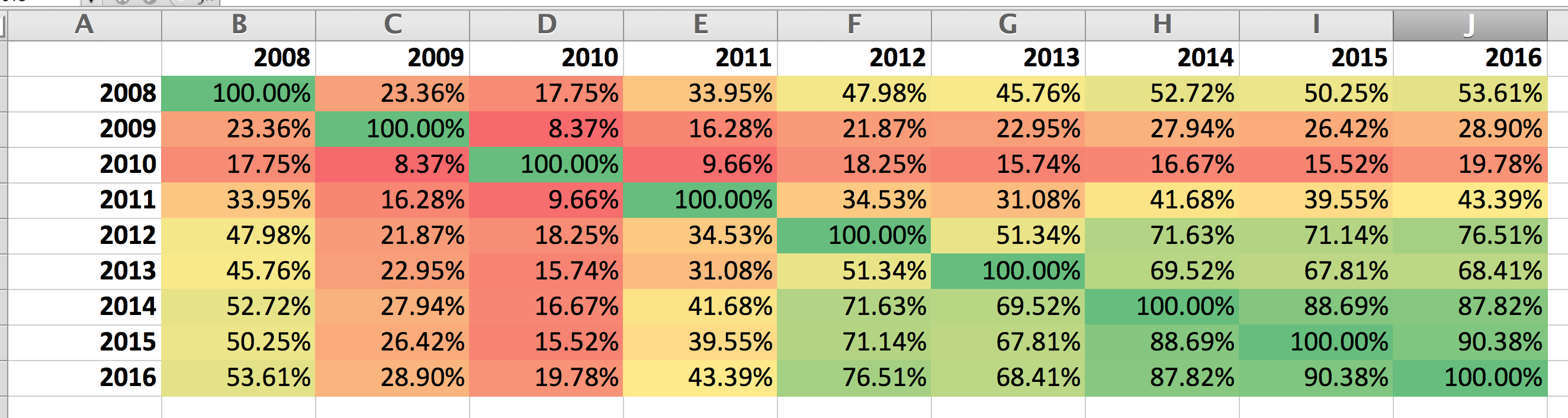
<p>Blog post similariy between 2008 and 2016. It's shocking to see how similar my blog posts have been since 2014. Based on the word clouds it seems all I write about is code and data.</p>
</div>
</li>