
In 2012 I did a simple analysis of IMDB to analyze the change in actor and actresses’s ages over time. At that point I limited the analysis to the top 50 movies each decade and hacked together a quick script to crawl and scrape the IMDB analysis. A couple of weeks ago I came across a great post by CuriousGnu that did a similar analysis across a larger set of movies but limited to movies since 2000. I reached out and they were kind enough to give me a DigitalOcean instance containing the data already loaded into MySQL. The analysis should be finished up tomorrow but I wanted to write this post up to share the mundane parts of the process. The janitorial part is critically important to an analysis and it’s important to get it right or the results will may be meaningless or even completely wrong. The NY Times interviewed a variety of data scientists and came away with the conclusion that 50 to 80 percent of a data scientist’s time is spent cleaning the data. This is no exception and I wanted to provide a sense of the effort and thought that goes into getting data into a state that’s actually useful.
Lucky for me I already had the data loaded and queryable in MySQL. Most of the time the data is scattered all over the place in a variety of different formats that require a slew of scripts to wrangle and manipulate the data into a useful format.
The first task was to get familiar with the data and I started by looking at sample rows from each of the tables. The table names were descriptive but it turned out that some of them were empty. Running a query that calculated the size of each provided a good idea of where the valuable data was - for my analysis the useful data lived in the title, name, cast_info, and person_info tables.
SELECT TABLE_NAME, table_rows, data_length, index_length,
round(((data_length + index_length) / 1024 / 1024),2) "Size in MB"
FROM information_schema.TABLES WHERE table_schema = "imdb";The next step was figuring out the way the tables related to one another. Since the field names were obvious this was extremely straightforward. The only nuances came due to an unconventional naming scheme - for example the title table contains the list of movies but the other tables map to it via a movie_id column. Similarly, the name table contains people but it’s referenced via person_id in other tables. They key part here was starting with a movie I know and confirming that the results made sense. In my case I chose my favorite movie, The Rock, and made sure that the results of my query made sense.
select *
from title t
join cast_info ci on t.id = ci.movie_id
join name n on ci.person_id = n.id
where t.id = 3569260;After getting a feel for the data it was time to actually think about the data necessary for the analysis. To see what was possible I examined the person_info table which contains a variety of information about each person - anywhere from birth and death dates, to spouse, to various names, to height. In my case looking at the birth and height gave me some ideas but I needed to extract these to make them useful. I ended up creating a table for each one and writing a series of queries to populate each one. This required looking at the format of the data in each of the rows and leveraging various combinations of the locate, substring, and cast commands to transform the text fields into something numeric. The birth date was straightforward since it came in two styles - one was just a year and the other was the full birth day with day and month.
insert into person_birth
SELECT person_id, cast(info as UNSIGNED)
FROM person_info
WHERE info_type_id = 21
AND length(info) = 4;
-- Birthdate is full date so just take the year
insert into person_birth
SELECT person_id, cast(substring(info, locate(' ', info, 4) + 1, 4) as unsigned)
FROM person_info
WHERE info_type_id = 21
AND length(info) > 4;Height was a bit more difficult since it came in a variety of formats. Some were in centimeters, while others were in feet, while others were in feet and inches, with a small fraction having partial inches. Each of these required a complicated series of MySQL commands to convert to inches.
insert into person_height
SELECT person_id, cast(replace(info, ' cm','') as unsigned) * 0.393701
FROM person_info
WHERE info_type_id = 22
AND info like '%cm';
-- No inches
insert into person_height
SELECT person_id, substring(info, 1, locate('\'', info) - 1) * 12
FROM person_info
WHERE info_type_id = 22
AND info not like '%cm'
AND info not like '%/%'
AND info not like '%"%';
-- No fractional inches (would also work for no inches but playing it safe)
insert into person_height
SELECT person_id, substring(info, 1, locate('\'', info) - 1) * 12 + substring(info, locate('\'', info) + 1, locate('"', info) - locate('\'', info) - 1)
FROM person_info
WHERE info_type_id = 22
AND info not like '%cm'
AND info not like '%/%'
AND info like '%"%';
-- Fractional inches
insert into person_height
select person_id, cast(base_height as decimal) + cast(numerator as decimal)/cast(denominator as decimal)
from (
SELECT person_id, info, substring(info, 1, locate('\'', info) - 1) * 12 + substring(info, locate('\'', info) + 1, locate('"', info) - locate('\'', info) - 1) as base_height,
substring(substring(info, locate(' ', info, 5) + 1, 3), 1, locate('/', substring(info, locate(' ', info, 5) + 1, 3))-1) as numerator,
substring(substring(info, locate(' ', info, 5) + 1, 3), locate('/', substring(info, locate(' ', info, 5) + 1, 3)) +1 ) as denominator
FROM person_info
WHERE info_type_id = 22
AND info not like '%cm'
AND info like '%/%'
AND info like '%"%'
) temp;Finally it was time to dive into the data. The first query I decided to write was to look at the average age of actors and actresses by year. Writing the query and doing a quick explain caused me to add a few indices to improve the performance but even then it still took over 20 minutes to execute. Having used Vertica and Redshift in the past I knew a columnar database would help but I wanted to keep it free. This led me to MonetDB.
Somewhat remarkably, installing and setting up MonetDB was a breeze but I had a two hiccups migrating the data. One was creating the equivalent tables in MonetDB which had a slightly different syntax from MySQL and required a bit of trial and error to work through. The other was the actual export of data from MySQL in a way that was also easy to load into MonetDB. I ended up settling on a CSV export that also took into account the various ways to delimit, escape, and enclose the different fields. After getting the migration to work on one table it was just a series of copy and pastes to get the other tables over.
-- MySQL export
select * from title into outfile '/tmp/title.csv' fields terminated by ',' enclosed by '"' escaped by "\\" lines terminated by '\n';
-- MonetDB import
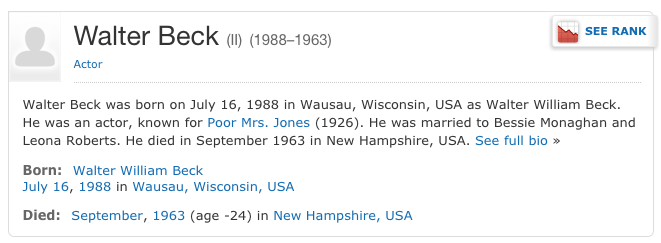
COPY INTO title from '/tmp/title.csv' USING DELIMITERS ',','\n','"' NULL AS '\\N';I had no experience with MonetDB and didn’t know what to expect with this entire series of steps being a waste of time. I expected some improvement and it turns out the query that took over 20 minutes to run in MySQL was able to run in just over 30 seconds in MonetDB. I was off to the races. I spent the next bit of time QAing the data and dealing with outliers and edge cases. Some were due to mistakes I made - for example not filtering cast members to only include actors and actresses which manifested itself in an actor that lived to be over 2000 years old. This turned out to be a movie about Socrates with one of the writers being Plato. Some simply uncovered weird data - there’s a movie, 100 Years, which is scheduled to be released in 2115 and led to some old actors and actresses. While others were clearly data mistakes - actors who were born after they died, for example Walter Beck who was born in 1988 but passed away in 1964.
Dealing with these was an iterative process. I ended up settling on removing all non actors and actresses from the queries as well as limiting my dataset to movies produced between 1920 and 2015 while also eliminating all combinations where a movie was produced before a birth. These edge cases are infrequent enough that they most likely wouldn’t have had any impact on the results but going through this process gives us confidence in what we’re doing. The next step is actually going through the analysis which I hope to finish up tomorrow.
If you’re interested in the code, it’s up on GitHub; and if you’re interested in the data contact me and I can share a snapshot of the DigitalOcean instance that contains the data in both MySQL and MonetDB.